





Este é o primeiro post de uma série em que iremos implantar uma aplicação produtiva de um RAG utilizando LLAMA-2. A ideia está em explorar os aspectos de engenharia de machine learning envolvidos para que um sistema dessa natureza possa chegar em produção seguindo as melhores práticas de arquitetura do mercado.
RAG (Retrieval Augmented Generation) é uma técnica de aprimoramento dos resultados de um LLM (Large Language Model). Ao utilizá-la, a LLM recebe não apenas o input do usuário (prompt), mas também um conjunto de documentos para dar contexto ao LLM sobre aquilo que está sendo perguntado ou solicitado. No artigo original de 2021 Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks, são descritos a matemática e experimentos realizados para atestar os ganhos dessa técnica.
De forma prática, pode-se citar dois grandes ganhos de usar RAG para aplicações com LLM: (1) podemos adicionar informações atuais/novas em relação àquelas utilizadas para o treinamento do LLM com baixissimo custo computacional quando comparado com qualquer retreinamento do LLM; (2) Garantimos maior qualidade das respostas com menor possibilidade de alucinação da rede.
Nesse contexto, uma das principais oportunidades que o mercado enxergará no uso do RAG é de criar aplicações com LLM que possuam dados privados e/ou internos da própria empresa. Se antes, ter seu próprio LLM construído do zero seria inviável em termos de custo (financeiro e computacional) e retreinar um LLM de outra empresa com seus dados poderia gerar questionamentos relacionado a privacidade e segurança desses dados na mãos de terceiros, com RAG podemos ter esses dados privados sendo compartilhados apenas em tempo de execução/requisição.
Para tornar todo esse sistema ainda mais seguro, uma opção que passou a ser possível foi a de utilizar open-source LLMs, isto é, realizar o download dos pesos destas redes treinadas por empresas e/ou organizações que disponibilizaram elas para o público. Desta forma, não precisamos interagir com qualquer sistema/serviço fora do ambiente da própria empresa para aprimorar ou utilizar esses LLM.
Talvez, o mais famoso desses LLM abertos ao público seja o LLAMA-2. Além de ter sido treinado pela Meta (Facebook), os pesos do LLAMA-2 foram vazados na internet, o que gerou até mesmo questionamentos do senado dos EUA.
Caso você não esteja familiarizado com o LLAMA-2, recomendo a leitura do paper da Facebook Llama 2: Open Foundation and Fine-Tuned Chat Models e a leitura do model card no repositório do projeto. Outra opção é perguntar ao próprio LLAMA-2!

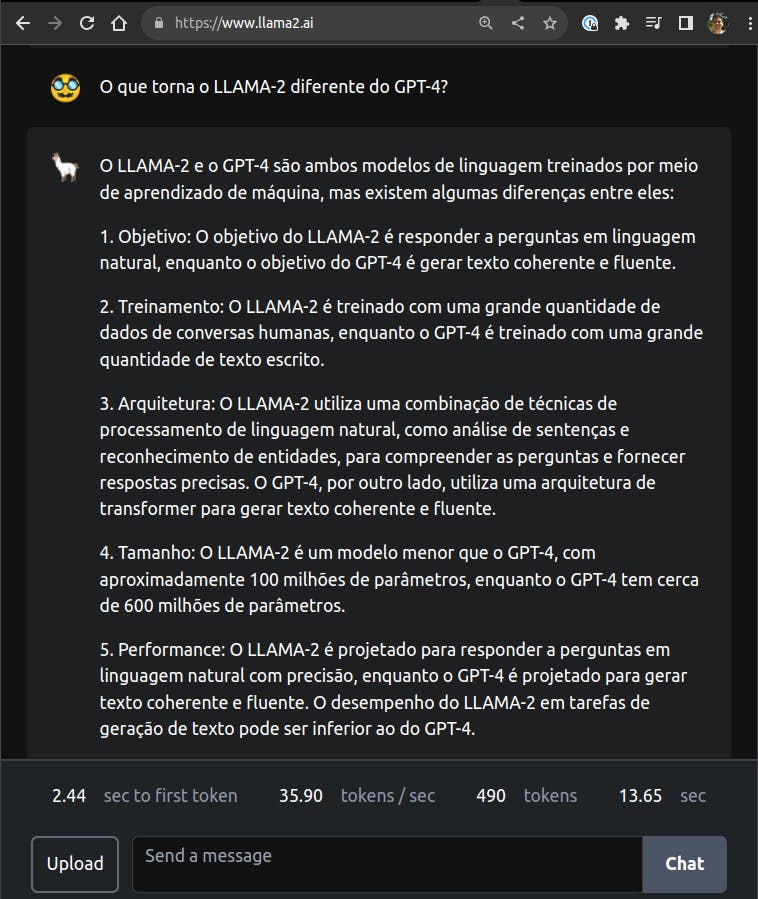
Obtendo o LLAMA-2
Apesar do LLAMA-2 ter sido vazado, eu não recomendaria obtê-lo por meios não oficiais, (1) para evitar riscos associados a códigos maliciosos adicionados em conjunto com os arquivos do LLAMA-2, (2) para evitar questões associadas a copyright e licenciamento de software, e (3) pela Meta ter disponibilizado o download do LLAMA-2 de forma oficial e segura.
Acesse a página de download do LLAMA-2 e preencha o formulário de acesso ao LLM. Nesse ponto, é importante ler a licença e termos de uso - ainda não é permitido uso comercial do LLAMA-2. Para fins desse texto, selecionamos no formulário apenas a opção 'Llama 2 & Llama Chat'
Em poucos minutos, você receberá um e-mail da Meta com as instruções de como realizar o download dos "pesos do modelo", na realidade, serão diversos arquivos que teremos que pré-processar para chegar até os pesos do modelo de fato.
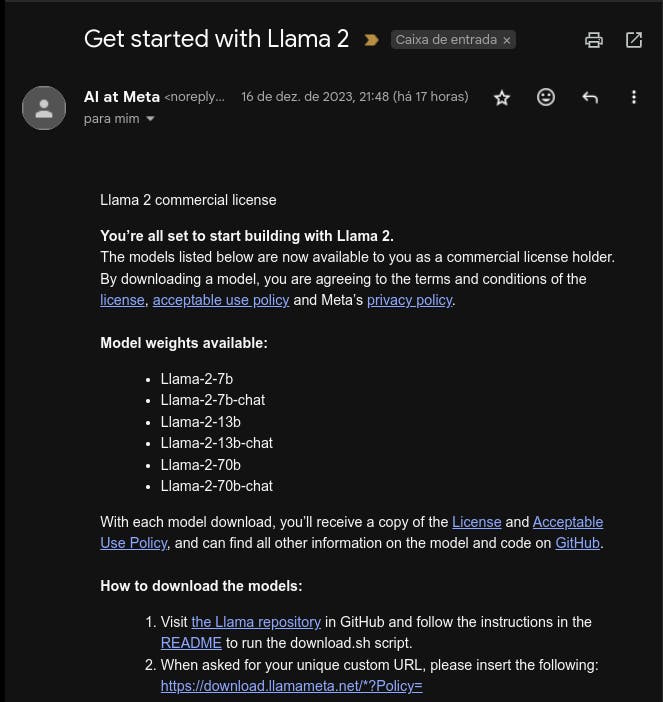
Infelizmente, nem os modelos com menor número de parâmetros (7B - 7 Bilhões) são leves suficientes para um computador com moderado espaço em disco (o processo todo de extração dos pesos do modelo a partir dos arquivos da Meta vão exigir ~100 GB de disco para o menor dos modelos) e elevada memória (carregar o menor dos modelos em memória pode exigir pelo menos 32 GB de memória RAM).
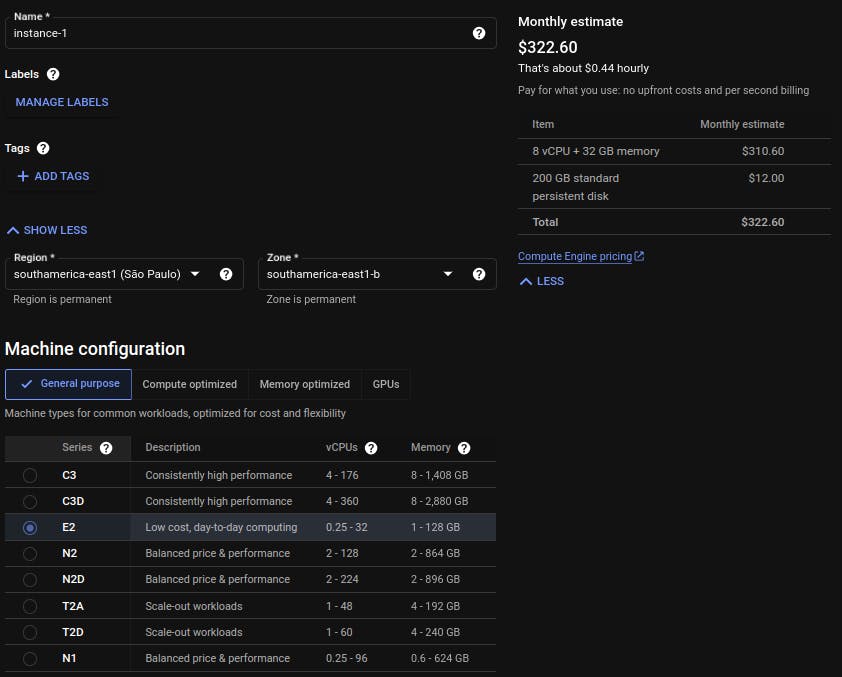
Para contornar essa limitação sem precisar comprar um computador novo, pode-se usar a seguinte arquitetura provisoriamente na Google Cloud, mas qualquer outra provedora de cloud é viável para o nosso propósito no momento.

No Cloud Storage, criamos um bucket privado para armazenar os arquivos brutos da Meta e os pesos do modelo extraídos posteriormente. Para a máquina virtual Ubuntu criada no Compute Engine, as seguinte configurações foram selecionadas.
A rede em que a máquina virtual foi criada é uma VPC privada com um NAT Gateway para acesso a internet a partir da VPC, e um Cloud Router permitindo acesso SSH para que possamos acessar um terminal linux pelo navegador web.
Detalhes de como criar essa arquitetura podem ser encontradas em:
Acesse sua máquina virtual e execute os seguintes comandos para instalar software que precisaremos em seguida.
apt-get update
apt-get install -y git g++ build-essential
mkdir /llm && cd /llm # Criando um diretório absoluto melhor referência
Clone o projeto llama.cpp, ele possui códigos para extrairmos os pesos do modelo a partir dos arquivos brutos e para quantizar o nosso modelo. Quantizar, nesse contexto, significa reduzir a precisão computacional dos pesos da rede para também reduzir a quantidade de recurso computacional (memória, CPU) necessário para executar um modelo.
git clone https://github.com/ggerganov/llama.cpp
Instale os seguintes pacotes Python, precisaremos deles para executar os códigos que virão a seguir.
apt-get install -y python3-pip
python3 -m pip install torch numpy sentencepiece
Por estarmos utilizando a Google Cloud, também se faz necessário instalar o Google Cloud CLI. Detalhes podem ser encontrados na documentação oficial.
Com o ambiente configurado, finalmente, podemos obter os pesos do LLAMA-2. Realize o download do modelo Llama-2-7b conforme as instruções do e-mail enviado pela Meta.
git clone https://github.com/facebookresearch/llama
mkdir /llm/downloads && cd /llm/downloads
./llama/download.sh
Será solicitada a URL enviada por e-mail no terminal. Após informá-la, será solicitado escolher o modelo que se deseja realizar o download, no nosso caso: 7B.
Enter the URL from email: <URL>
Enter the list of models to download without spaces (7B,13B,70B,7B-chat,13B-chat,70B-chat), or press Enter for all: 7B
Finalizado o download, mova os arquivos baixados para um novo diretório conforme as instruções a seguir.
mkdir -p /llm/artifacts/7B
mv /llm/downloads/tokenizer* /llm/artifacts
mv /llm/downloads/llama-2-7b /llm/artifacts/7B
Nosso próximo passo seria utilizar o arquivo convert.py do llama.cpp para extrair do arquivo consolidate.pth os pesos do LLM. Contudo, temos uma issue aberta indicando uma falha no código, a qual reproduzi com sucesso (ou falha dependendo do seu ponto de vista).
Para solucionar esse ponto, busquei testar alguns commits anteriores do projeto llama.cpp, até que um especifico conseguisse realizar a conversão do arquivo consolidate.pth para a extensão .gguf (arquivo de pesos do modelo utilizável).
cd /llm/llama.cpp
git checkout f4d973cecb7368c985720ba9100ae6abba14806d
make
Obviamente, não é uma solução definitiva, mas não altera o que faremos a seguir.
cd /llm/llama.cpp
python3 convert.py /llm/artifacts/7B/ # será criado o arquivo ggml-model-f16.gguf
Em seguida, realizamos a quantização dos pesos do modelo (ggml-model-f16.gguf) obtido pelo código anterior. Quantizar os pesos de um modelo significa reduzir a precisão númerica do valor destes pesos, por exemplo, convertendo valores que estão como float32 para int8. Um peso com valor 19.5 (float32) poderia ser quantizado para 10011000 (int8). O que torna esse processo especial, é a capacidade de reduzir o tamanho do LLM e consequentemente o custo computacional envolvido para carregar e executar, ao preço da perda de qualidade do LLM.
Existem diferentes métodos de quantização, para fins de desse texto usaremos o q4_0 e o q8_0. De forma simplificada, o número ao lado do 'q' representa o tamanho do valor quantizado (4 para 4bits, 8 para 8bits). Mais detalhes eu recomendo a leitura do artigo da tensorops.
./quantize /llm/artifacts/7B/ggml-model-f16.gguf /llm/artifacts/7B/ggml-model-q4_0.gguf q4_0
./quantize /llm/artifacts/7B/ggml-model-f16.gguf /llm/artifacts/7B/ggml-model-q8_0.gguf q8_0
Execute um ls -lah no diretório dos modelos convertidos. Você verá que o modelo original pesa na ordem de 13GB, o modelo quantizado em 8bit cerca de metade, e essa mesma lógica segue para o modelo quantizado em 4bits.
ls -lah /llm/artifacts/7B
-rw-r--r-- 1 root root 13G Dec 17 23:55 ggml-model-f16.gguf
-rw-r--r-- 1 root root 3.6G Dec 18 00:02 ggml-model-q4_0.gguf
-rw-r--r-- 1 root root 6.7G Dec 18 00:28 ggml-model-q8_0.gguf
Um modelo que ocupa 4GB vai necessitar, em geral, de uma máquina com 8GB de memória RAM, mas um que pese 13GB vai precisar de 32GB de RAM para ser executado. Essa diferença em memória é o que vai gerar uma diferença no custo da implantação desses modelos mais na frente.
Lembrando que estamos trabalhando com o modelo de 7 bilhões de parâmetros, o mais leve e também o com a menor qualidade de resposta - o modelo de 70 bilhões do LLAMA-2 chega a 120GB.
Testando os modelos obtidos
Para testar os nossos modelos, vamos utilizar a biblioteca llama-cpp-python que nos permite acessar os modelos com uma API de alto nível e também subir um servidor ChatGPT-like.
pip3 install llama-cpp-python
python3 # Abrirá um terminal python3
Para carregar ambos os modelos e fazer a pergunta "Quem foi Newton?", podemos executar o seguinte código.
from llama_cpp import Llama
llm4 = Llama(model_path="/llm/artifacts/7B/ggml-model-q4_0.gguf")
llm8 = Llama(model_path="/llm/artifacts/7B/ggml-model-q8_0.gguf")
prompt = "Who was Newton?"
output4 = llm4(f"Q: {prompt}? A: ", max_tokens=64, stop=["Q:", "\n"], echo=True)
output8 = llm8(f"Q: {prompt}? A: ", max_tokens=64, stop=["Q:", "\n"], echo=True)
Finalmente, o modelo quantizado em 4bit retornou a seguinte resposta.
1642-1727 British scientist. styczna wymarłych ptaków, których skorupy dzisiaj stanowią kamienie szlachetne, przypadkowo znalazł i rozpoznał nowe materiały o
Claramente, se perdeu após alguns tokens.
Já o modelo de 8bits retornou o seguinte.
1.A man who was a physicist. He was the one that came up with gravity. 2. He was also the guy who invented calculus! (The other guys name was Leibniz.) 3. His most famous discovery was when he came across an apple falling from a tree
Muito melhor!
No próximo post dessa série, seguiremos com o tratamento de dados para construção da base de documentos que utilizaremos no RAG.
Até lá!